The deep learning algorithm has made great progress in recent years, and it has also sent a slogan to the entire artificial intelligence field. However, the classifiers and feature modules in the deep learning system are self-learning. The interpretability of neural networks has become a problem that plagues researchers. People often refer to them as black boxes. But understanding how deep neural networks work is critical to explaining how they make decisions and building more powerful systems.
Recently, DeepMind released its latest research on the interpretability of neural networks by deciding certain neuron groups in the network to determine whether it is important for the entire network. The core findings are as follows:
Interpretable neurons (such as "cat neurons") are no more important than neurons that are difficult to interpret.
A well-normalized network is more adaptive to the operation of deleting neurons.
Deep neural networks consist of many independent neurons that combine in a complex and counter-intuitive way to solve challenging tasks. This complexity gives the neural network a powerful function, but it also makes it a confusing and opaque black box.
Understanding how deep neural networks work is critical to explaining their decisions and building more powerful systems. Imagine how difficult it is to make a watch without knowing how the various gears fit. In the field of neuroscience and deep learning, one way to understand neural networks is to study the effects of individual neurons, especially those that are easy to interpret.
We are about to publish a study on the importance of generalization in a single direction at the Sixth International Conference on Learning and Characterization (ICLR), which uses a method inspired by experimental neuroscience—exploring the effects of damage—to determine deep neural networks. The importance of group neurons in the group, and the importance of neurons that are easier to explain.
By removing individual neurons and neuron groups, we measured the impact of disruption on performance. In the experiment, we have two amazing discoveries:
Many previous studies have attempted to understand individual neurons that are easy to interpret (such as "cat neurons", or neurons in the deep network that only respond to images of cats), but we found that these interpretable neurons are no better than Neurons that are difficult to interpret are more important.
Compared to networks that can only classify images that have already been seen, networks that correctly classify unseen images have better resilience to neuron missing. In other words, a network with good generalization is much less dependent on unidirectional than a network with poor generalization.
▌ "Cat neurons" may be easier to explain, but they are not more important
In neuroscience and deep learning, easily interpretable neurons ("selective" neurons) have been extensively analyzed, and they only respond positively to images of a single input category, such as dogs. In deep learning, this has led researchers to pay attention to cat neurons, sentiment neurons, and parentheses neurons. However, the relative importance of these few highly selective neurons is still unknown compared to most neurons with low selectivity, more puzzling, and unexplained activity.
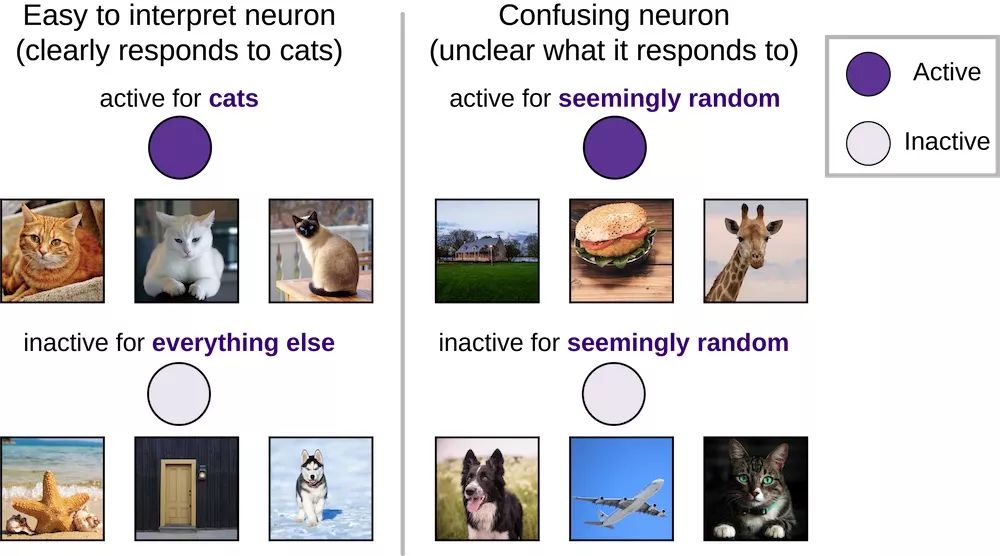
Compared with confusing neurons that respond positively or negatively to a seemingly random set of images, it is easier to have a clear response pattern (such as a positive response to a "dog" and a negative response to all other categories). Explanation.
To assess the importance of neurons, we measured the performance changes of neural networks in image classification tasks after deleting neurons. If a neuron is very important, removing it should have serious consequences, and network performance will be greatly reduced, and deleting an unimportant neuron should have no effect. Neuroscientists usually perform similar experiments, although they do not achieve the fine-grained precision necessary for these experiments, but are easily implemented in artificial neural networks.
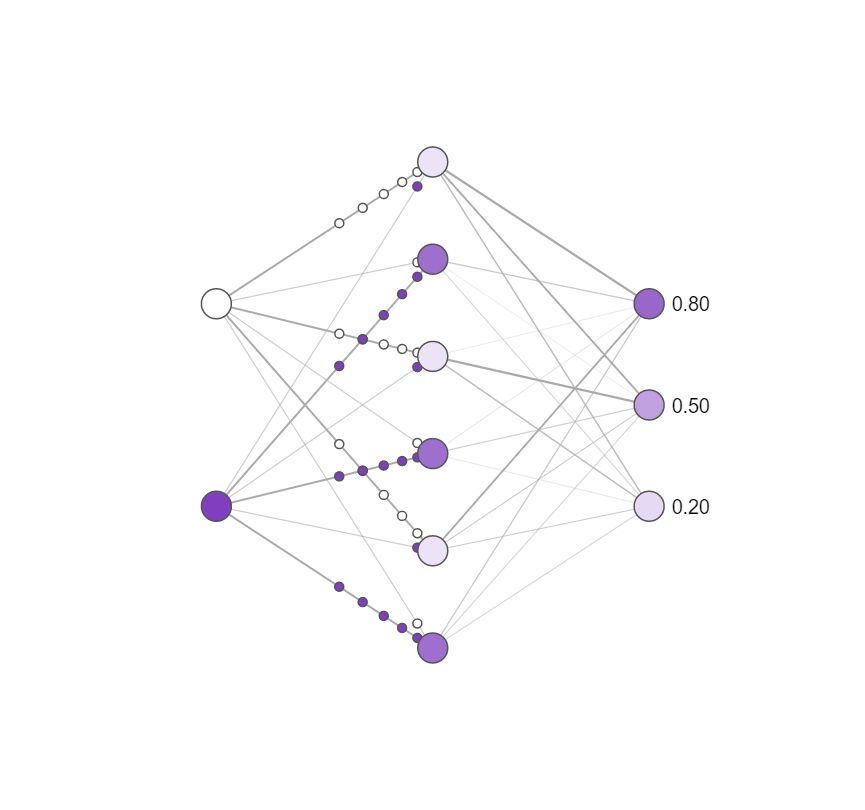
A conceptual diagram of the effects of neurons on simple neural networks. The darker the color, the more active the neurons. You can try to click on the hidden layer neurons on the original page to delete them and see the changes in the activity of the output neurons. Note that deleting only one or two neurons has little effect on the output, while deleting most neurons has a large impact, and some neurons are more important than others!
Surprisingly, we found that there is no relationship between selectivity and importance. In other words, "cat neurons" are no more important than confusing neurons. This finding echoes recent research in neuroscience, which has proven that confusing neurons can actually provide considerable information. In order to understand deep neural networks, our research cannot be limited to the most easily explained neurons.

Although "cat neurons" may be easier to explain, they are no more important than neurons that are confusing and have no apparent preference.
网络 More generalized network is less likely to crash
Although we want to create intelligent systems, we can only call them intelligent systems when they can be generalized to new scenarios. For example, if an image classification network can only classify the images of a particular dog it has seen, but not the latest image of the same dog, the network is useless. These systems are only useful when intelligently classifying new instances.
A recent paper by Berkeley, Google Brain, and DeepMind has won the best paper on ICLR 2017. The paper shows that deep networks can simply remember each image rather than learning in a more humane way (for example, understanding the abstract concept of "dogs").
However, we have not had a clear answer as to whether the neural network has learned the solution to determine the generalization ability. By progressively deleting larger and larger neuron populations, we found that a generalized network is much more robust to deleting neurons than simply memorizing the networks of images previously seen in training. In other words, a more generalized network is less likely to crash (although this may happen).
As more and more neuron populations are removed, the performance of generalized networks declines significantly slower.
By measuring the robustness of the neural network in this way, we can assess whether the network is "cheating" by exploiting our undesired memory capabilities. Understanding how the network changes when it is remembered will help us build new networks with better generalization capabilities.
Analytical methods inspired by neuroscience
These findings demonstrate that techniques inspired by experimental neuroscience can help us understand the capabilities of neural networks. Using these methods, we found that highly selective independent neurons are no more important than non-selective neurons, and that a generalized network is less dependent on independent neurons than a network that simply memorizes training data. These results suggest that the importance of independent neurons may be far less important than we think.
By explaining the role of all neurons, not just those that are easy to understand, we hope to better understand the inner workings of neural networks and use this understanding to build smarter and more versatile systems.
A manual pulse generator (MPG) is a device normally associated with computer numerically controlled machinery or other devices involved in positioning. It usually consists of a rotating knob that generates electrical pulses that are sent to an equipment controller. The controller will then move the piece of equipment a predetermined distance for each pulse.
The CNC handheld controller MPG Pendant with x1, x10, x100 selectable. It is equipped with our popular machined MPG unit, 4,5,6 axis and scale selector, emergency stop and reset button.
Manual Pulse Generator,Handwheel MPG CNC,Electric Pulse Generator,Signal Pulse Generator
Jilin Lander Intelligent Technology Co., Ltd , https://www.landerintelligent.com