Reinforcement learning models often rely on the careful design of external reward mechanisms, and there are limitations in model training cost control and scalability. OpenAI researchers proposed a new reinforcement learning model training method that uses the agent's "curiosity" as the internal reward function. There is no need for external rewards during training. The generalization is good. After 54 environmental tests, the effect is outstanding.
Reinforcement learning models rely to a large extent on the careful design of the agent's external environment rewards. However, the way to mark each environment with dense rewards designed by hand is not scalable, which requires the development of the intrinsic reward function of the agent. Curiosity is an intrinsic reward function, which uses prediction errors as a reward signal.
In this article, for the first time, we conducted a large-scale study purely based on curiosity-driven learning in 54 standard benchmarking environments (including a series of Atari games) without setting any external rewards. The results obtained are surprising and show that there is a high degree of consistency between the intrinsic curiosity goal reward and the hand-designed extrinsic reward mechanism in many game environments.
Reinforced learning "curiosity" model: training does not require external rewards, it is all on your own
We studied the effect of using different feature spaces to calculate prediction errors, and showed that random features are sufficient for the benchmarks of many popular reinforcement learning games, but the learned features seem to have higher generalizations. Sex. (For example, it can be migrated to the new level of "Super Mario Bros.").
We have conducted large-scale empirical research on agents, which are purely driven by intrinsic rewards in various simulated environments, which is the first time in the industry. In particular, we choose a curiosity model based on dynamics and intrinsic rewards. Because this model has strong scalability and parallelism, it is very suitable for large-scale experiments.

Figure 1: A collection of snapshots of the 54 environments used in this study. Our research has shown that agents can make progress without external rewards or end signals by relying on curiosity alone.
For related videos, results, code and models, see https://pathak22.github.io/large-scale-curiosity
Our idea is to express the intrinsic reward as an error in predicting the behavioral consequences of the agent in the current state, that is, the forward dynamic prediction error of the agent's learning. We thoroughly investigated the dynamics-based curiosity in 54 environments: these scenarios include video games, physics engine simulations, and virtual 3D navigation tasks, as shown in Figure 1.
To better understand curiosity-driven learning, we further studied the key factors that determine its performance. Predicting the future state in the high-dimensional original observation space (such as an image) is a very challenging problem. Learning the dynamics in the auxiliary feature space can improve the results.
However, how to choose such an embedded space is a key and unresolved research problem. Through the simplification of the system, we have studied the effect of encoding the information observed by the agent with different methods, so that the agent can perform well on its own curiosity mechanism.
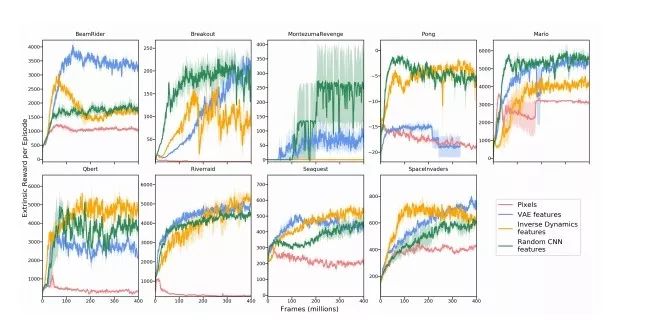
The picture above is a comparison of 8 selected Atari games and feature learning methods of Super Mario Bros. The evaluation curve in the figure shows the average reward score (including standard error) obtained by the agent purely through curiosity training, without external rewards and level end signals.
We have seen that agents driven purely by curiosity can collect rewards in these environments without using any external rewards in training.
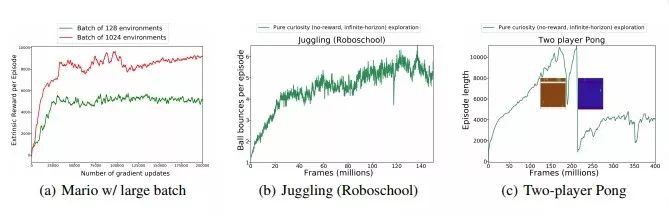
Figure 3: Left: Comparison of RF training methods with different batch sizes. Training does not use external rewards. Medium: The number of ball bounces in the Juggling (Roboschool) environment. Right: The average level of the multiplayer Pong environment
In order to ensure dynamic and stable online training, we believe that the required embedding space should be: (1) compact in dimensionality, (2) able to store enough observed information, and (3) a fixed function based on observation information.
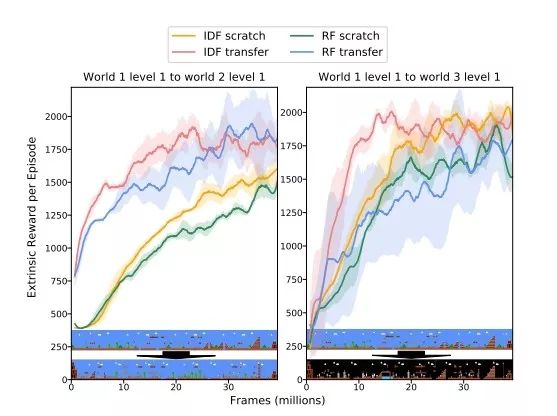
Figure 4: Generalization experiment in the game environment of "Super Mario Bros." The left picture shows the migration result from level 1-1 to level 1-2, and the right picture shows the migration result from level 1-1 to level 1-3. Below is the mapping from the source environment to the target environment. All agents have no external rewards during the training process.
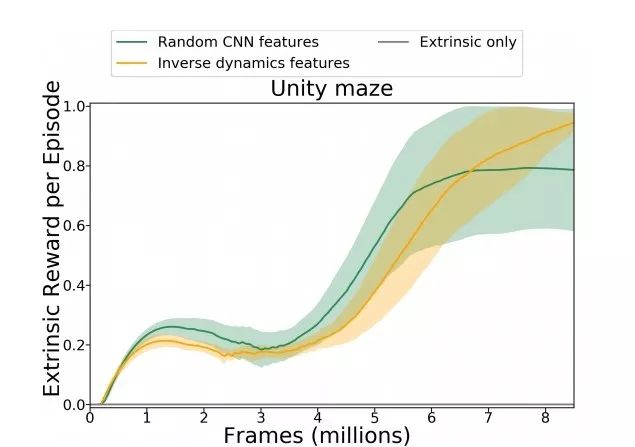
Figure 5: The average external reward in the Unity environment when the terminal external reward + curiosity reward is used for combined training. Note that the value of the curve for training only through external rewards is always zero (shown as the bottom line in the figure)
Our research shows that encoding observations through random networks is a simple and effective technique that can be used to build curiosity models in many popular reinforcement learning benchmarks. This may indicate that many popular reinforcement learning video game tests are not as visually complex as commonly believed.
Interestingly, although random features are sufficient for the benchmark tests of many popular reinforcement learning games, the learned features seem to be more generalizable (such as those promoted to "Super Mario Bros." In a new level).
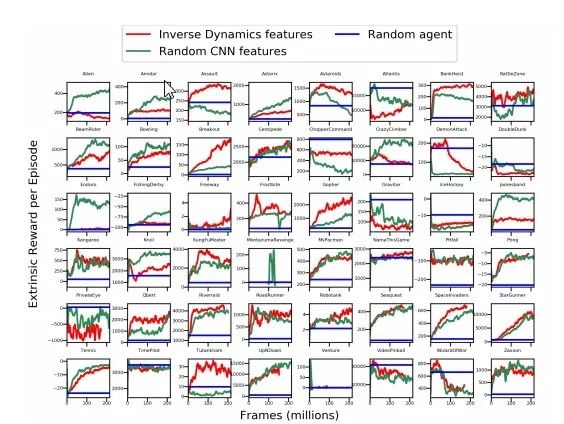
The figure above shows the performance results in all Atari gaming environments. We found that the curiosity model trained with pixels does not perform well in any environment, and the performance of VAE features is not better than random features and inverse dynamics features, and sometimes even worse.
In addition, in 55% of Atari games, inverse dynamic training features perform better than random features. The analysis shows that the random feature that models curiosity is a simple and powerful baseline standard, and may perform well in half of the Atari game scenes.
summary
(1) We have conducted large-scale research on curiosity-driven models in various environments. These scenarios include: Atari game set, "Super Mario Bros." game, virtual 3D navigation in Unity, Roboschool environment, etc.
(2) We have extensively studied different feature spaces for learning dynamics-based curiosity, including random features, pixels, inverse dynamics, and variational autoencoders, and evaluated the generalizability of these spaces in invisible environments Sex.
(3) Limitations: We have observed that if the agent itself is the source of randomness in the environment, it can reward itself without making any actual progress. We have empirically proved this limitation in 3D navigation tasks, in which the agent can control different parts of the environment.
Future direction
We propose a simple and extensible method to learn non-trivial behaviors in different environments without any reward function or end signal. A surprising finding of this article is that random features perform well, but the learned features seem to be better in generalizability. We believe that once the environment is sufficiently complex, the learning of features will become more important, but we decided to leave this issue to the future.
Our higher goal is to be able to use many unlabeled (that is, no reward function designed in advance) environment to improve the performance of the task of interest. In view of this, showing good performance in an environment with a universal reward function is only the first step of our research, and future results may include the realization of the migration from the unlabeled environment to the labeled environment.
OTG USB Flash Drive is one serial of USB flash drive,which is hot selling right now and widely used on different mobiles,including Iphone and all smart phones which can support OTG function.More and more people choose it since it is quite small and very easy to take with.
There are mainly 4 kinds of OTG USB flash drive as below:
1. 2 IN 1 USB flash drive with micro(or Android)

2. 2 IN 1 USB flash drive with type C.

3.2 IN 1 USB flash drive with lighting for Iphone.

4.3 IN 1 OR 4 IN 1 USB flash drive with lightning/micro/USB C.




Most OTG USB flash drives start with 8GB until 256GB.You may also look for 1TB 2TB OTG USB memory stick but you will find the 1TB 2TB OTG USB flash drive you bought not working soon when you want to save more and more files,or even some files are missing.Why? Because they are not real full capacity!
We only do real full capacity as promised,and no upgrade or fake capacity from us.
otg usb flash drive, otg usb flash drive for apple iphone, best 3 in 1 usb flash drive,best type c usb flash drive,4 in 1 usb memory stick
Shenzhen Konchang Electronic Technology Co.,Ltd , https://www.konchangs.com