It has recently been learned that natural language processing is a larger branch in machine learning. There are many challenges. For example: how to segment words, identify entity relationships, relationships between entities, relationship network display, etc.
I used Jieba + Word2vec + NetworkX to do a natural language analysis. The corpus is the Heavenly Dragon Slayer. Many people used to analyze and deal with Jin Yong's martial arts novels, hoping to bring some different places. Take a few pictures to see:

A similar diagram of all characters is connected.
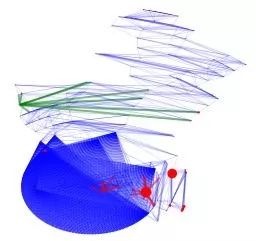
The relationship is the same as above. Multi-center structure
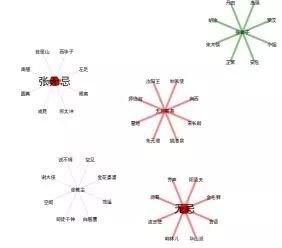
A network diagram centered on Zhang Wuji's different identities.
The differences in this analysis are mainly:
1, Word2Vec similarity results - as a late social network weight
2. Analysis and display in NetworkX
The combination of the above two methods can greatly reduce the time required to read articles in daily work. With machine learning, you can automatically extract the entity information in the article from the beginning to the end, saving a lot of time and cost. There are scenes that are used in various jobs. If you are interested, you can contact and cooperate.
Let's take a look at what you can find with Word2Vec+NetworkX.

First, the analysis results
Different attributes of the entity (Zhang Wuji's total vest)
Zhang Wuji, Wuji, Zhang Jiaozhu, Wuji brother, Zhang Gongzi. The same Zhang Wuji has multiple identities, and different identities are associated with different people, with different similarities.
Let’s take a look at the picture:
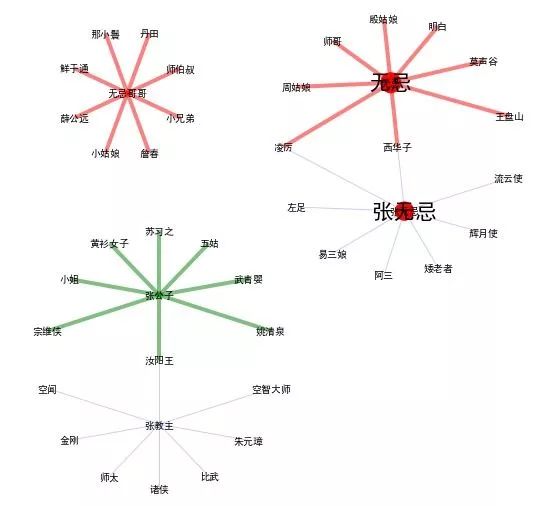
The jealous brother is a too intimate name, generally not shouting. It seems that the similarity with this word is a strange character.
It is a name that can be called by the peers or elders after the relationship is cooked. There are also Zhou girl, Yin girl, etc.
Zhang Wuji is the name of GM, and everyone can call it closely with the vest.
Zhang Gongzi is a polite honor. For example, yellow shirt women, Xiangyang Wang, etc.
Zhang Jiaozhu is the title. It is necessary to respect, but also to say that it is not very familiar, and sometimes it is somewhat hostile. For example: Zhu Yuanzhang
Note:
1, the picture is Networkx based on Word2vex drawn, the above description is my manual analysis.
2. Zhao Min is not in the above network diagram. Word2Vec calculated that Zhang Wuji and Zhao Min are not too similar. Some are beyond my expectations. I recalled carefully that when I read this book, I suddenly found out that the two were together, which was quite awkward. In retrospect, the two people in the world are married, and if they become a real world, the relationship between the two is relatively high.

Second, the realization process
The main steps:
Prepare corpus
Text file of Yitian Shoulongji novel
Custom word segmentation dictionary (the name of the character in the novel, there are ready-made online, about 180)
Stop word list
Preparation tool
Python Pandas, Numpy, Scipy (Standard Library)
Jieba (Chinese word segmentation)
Word2vec (word vectorization tool, you can calculate the level of detail between words)
Networks (network diagram tool for demonstrating complex network relationships
Data preprocessing
Text file is forwarded to utf8 (pandas)
Text file clause, participle (Jieba)
Text file clauses, participles, analysis of part of speech, mainly name (Jieba)
Update the custom dictionary and re-partition (the whole process takes several times until you are satisfied)
Manually deleted a small number of people (the wording error rate is not high, but there are still some. For example: Zhao Min smiled, can be identified by a person named Zhao Minxiao. This part of the work still needs to be done manually. Unless there is better The word segmentation tool, or a word segmentation tool that can be trained, can solve this problem.
Word2Vec training model. This model can calculate the similarity between two people
Adopt 300 dimensions
Filter word frequency less than 20 times
Sliding window is 20
Downsampling: 0.001
Generate an entity relationship matrix.
I didn't find the ready-made library on the Internet, I wrote one myself.
N*N dimension. N is the number of names.
Fill the entity relationship matrix with the above WordVec model
NetworkX generates a network map
Node is a person's name
The edge is the line between two nodes. That is the relationship between two people.
Third, part of the code to achieve
initialization
Import numpy as np
Import pandas as pd
Import jieba
Import jieba.posseg as posseg
%matplotlib inline
Data segmentation, cleaning
Renming_file = "yttlj_renming.csv"
Jieba.load_userdict(renming_file)
Stop_words_file = "stopwordshagongdakuozhan.txt"
Stop_words = pd.read_csv(stop_words_file,header=None,quoting=3,sep=" ")[0].values
Corpus = "yttlj.txt"
Yttlj = pd.read_csv(corpus,encoding="gb18030",header=None,names=["sentence"])
Def cut_join(s):
New_s=list(jieba.cut(s,cut_all=False)) #分è¯
#print(list(new_s))
Stop_words_extra =set([""])
For seg in new_s:
If len(seg)==1:
#print("aa",seg)
Stop_words_extra.add(seg)
#print(stop_words_extra)
#print(len(set(stop_words)| stop_words_extra))
New_s =set(new_s) -set(stop_words)-stop_words_extra
#Filter punctuation
#Filter stop words
Result = ",".join(new_s)
Return result
Def extract_name(s):
New_s=posseg.cut(s) #å–è¯
Words=[]
Flags=[]
For k,v in new_s:
If len(k)>1:
Words.append(k)
Flags.append(v)
Full_wf["word"].extend(words)
Full_wf["flag"].extend(flags)
Return len(words)
Def check_nshow(x):
Nshow = yttlj["sentence"].str.count(x).sum()
#print(x, nshow)
Return nshow
# extract name & filter times
Full_wf={"word":[],"flag":[]}
Possible_name = yttlj["sentence"].apply(extract_name)
#tmp_w,tmp_f
Df_wf = pd.DataFrame(full_wf)
Df_wf_renming = df_wf[(df_wf.flag=="nr")].drop_duplicates()
Df_wf_renming.to_csv("tmp_renming.csv",index=False)
Df_wf_renming = pd.read_csv("tmp_renming.csv")
Df_wf_renming.head()
Df_wf_renming["nshow"] = df_wf_renming.word.apply(check_nshow)
Df_wf_renming[df_wf_renming.nshow>20].to_csv("tmp_filtered_renming.csv",index=False)
Df_wf_renming[df_wf_renming.nshow>20].shape
#Manual editing, delete a small number of non-personal names, the name of the wrong person
Df_wf_renming=pd.read_csv("tmp_filtered_renming.csv")
My_renming = df_wf_renming.word.tolist()
External_renming = pd.read_csv(renming_file,header=None)[0].tolist()
Combined_renming = set(my_renming) |set(external_renming)
pd.DataFrame(list(combined_renming)).to_csv("combined_renming.csv",header=None,index=False)
Combined_renming_file ="combined_renming.csv"
Jieba.load_userdict(combined_renming_file)
# tokening
Yttlj["token"]=yttlj["sentence"].apply(cut_join)
Yttlj["token"].to_csv("tmp_yttlj.csv",header=False,index=False)
Sentences = yttlj["token"].str.split(",").tolist()
Word2Vec vectorization training
# Set values ​​for various parameters
Num_features = 300 # Word vector dimensionality
Min_word_count = 20 # Minimum word count
Num_workers = 4 # Number of threads to run in parallel
Context = 20 # Context window size
Downsampling = 1e-3 # Downsample setting for frequent words
# Initialize and train the model (this will take some time)
From gensim.models import word2vec
Model_file_name = 'yttlj_model.txt'
#sentences = w2v.LineSentence('cut_jttlj.csv')
Model = word2vec.Word2Vec(sentences, workers=num_workers,
Size=num_features, min_count = min_word_count,
Window = context,
Sample = downsampling
)
Model.save(model_file_name)
Establish an entity relationship matrix
Entity = pd.read_csv(combined_renming_file,header=None,index_col=None)
Entity = entity.rename(columns={0:"Name"})
Entity = entity.set_index(["Name"],drop=False)
ER = pd.DataFrame(np.zeros((entity.shape[0],entity.shape[0]),dtype=np.float32),index=entity["Name"],columns=entity["Name"] )
ER["tmp"] = entity.Name
Def check_nshow(x):
Nshow = yttlj["sentence"].str.count(x).sum()
#print(x, nshow)
Return nshow
ER["nshow"]=ER["tmp"].apply(check_nshow)
ER = ER.drop(["tmp"], axis=1)
Count = 0
For i in entity["Name"].tolist():
Count +=1
If count % round(entity.shape[0]/10) ==0:
Print("{0:.1f}% relationship has been checked".format(100*count/entity.shape[0]))
Elif count == entity.shape[0]:
Print("{0:.1f}% relationship has been checked".format(100*count/entity.shape[0]))
For j in entity["Name"]:
Relation =0
Try:
Relation = model.wv.similarity(i,j)
ER.loc[i,j] = relation
If i!=j:
ER.loc[j,i] = relation
Except:
Relation = 0
ER.to_hdf("ER.h5","ER")
NetworkX shows people diagram
Import networkx as nx
Import matplotlib.pyplot as plt
Import pandas as pd
Import numpy as np
Import pygraphviz
From networkx.drawing.nx_agraph import graphviz_layout
Infrared Pen,Infrared Touch Pen,Infrared Tablet Stylus Pen,Infrared Stylus Pencil
Shenzhen Ruidian Technology CO., Ltd , https://www.szwisonen.com