Lei Feng network: In order to ensure the professionalism of the content, this article has invited experts in the field of deep learning chip checks to review, author ironclad.
Recently, Intel said it will launch CPU Knights Mill for the deep learning market in 2017. According to Intel’s announcement, the Knights Mill can act as a host processor and can efficiently handle deep learning applications without additional accelerators or coprocessors. It can be said that following China’s Cambrian and Starlight Smart One, IBM’s True North, Google’s TPU, and Nvidia’s custom GPUs for artificial intelligence, Intel is also competing in this field.
So, what are the features of this multi-deep learning processor and what are its advantages and disadvantages?
| CPU, GPU: with car freightAfter Intel developed a custom GPU for artificial intelligence and adhered to the DGX-1 system, Intel was not far behind. After acquiring deep learning startup company Nervana Systems, Intel also announced a new member of the Xeon Phi family for deep learning. The field of deep learning processors opens up new battlefields.

In the recent past, Intel also released some Xeon Phi benchmark results, which are summarized as follows:
1. The four Knights Landing Xeon Phi chips are 2.3 times faster than the four GPUs;
2. In a multi-node system, the Xeon Phi chip can extend 38% better than the GPU.
The system of 3,128 Xeon Phi servers is 50 times faster than the single Xeon Phi server, which implies that the Xeon Phi server is very scalable;
4. When using the Intel optimized Caffe Deep Learning Framework, the Xeon Phi chip is 30 times faster than the standard Caffe.
In a nutshell, Intel's many-core chips are more efficient in deep learning than Nvidia's GPUs .
However, Nvidia also counterattacked, claiming that this was Intel's use of its old benchmark results and stated that:
1. If Intel uses the updated Caffe AlexNet to achieve results, it will find that the four previous-generation NVIDIA Maxwell GPUs are actually 30% faster than the four Intel Xeon Phi server clusters .
2. In addition, once the Nvidia GPU is transferred from the 28nm planar process to the 16nm FinFET process, the GPU's performance and efficiency will be greatly improved.
3. For deep learning, Nvidia also emphasizes that fewer high performance nodes will be better than more low performance nodes anyway. Taking its latest DGX-1 as an example, the DGX-1 is considered to be a little faster than the 21 Xeon Phi server clusters and 5.3 times faster than the four Xeon Phi server clusters.

The author believes that Intel's many-core chips also absorb the advantages of GPUs to a certain extent, and they have good performance, but in the short term, they still have the advantage of GPUs. However, no matter whether it is a lot-core chip for artificial intelligence or a customized version of GPU, it is essentially not a dedicated processor. Instead, it actually takes the existing and relatively mature architecture and technical achievements to deal with new-born artificial intelligence. Revolutionary technological breakthrough.
In fact, Intel and Nvidia are using existing mature technologies to meet the needs of deep learning. Many-core chips and custom-built GPUs are still CPUs and GPUs in essence, but not specialized chips for deep learning. It will inevitably bring about some inherent deficiencies. For example, using deep core chips and GPUs to run deep learning is similar to using cars to pull goods. Due to the characteristics of the cars themselves, there is a certain gap between the cargo transportation capacity and the truly high-powered, high-load trucks. Similarly, even if the technology is relatively mature, Intel and Nvidia's chips have advantages in integration and manufacturing processes. However, because CPUs and GPUs are not specialized chips for deep learning, their operating efficiency must be relatively high compared to professional chips. influences.
| DSP: real neural network chip and a gapOn June 20, the China National Key "Digital Multimedia Chip Technology" State Key Laboratory announced in Beijing that China's first embedded NPU (neural network processor) chip was born, and it has been applied to the world's first embedded video processing chip "Starlight Smart One." number".
According to the media, “Starlight Intelligence One contains the most advanced biological brain neural network bionics innovation technology in the field of computer science, and it is also a realization of 'bend overtaking' in China’s IC industry, which relies heavily on imported products abroad. We have made great efforts, which indicates that China has made major breakthroughs in the research and development of the neural network processor field, and that the development of the video surveillance industry in China has moved from the analog and digital eras to the smart era, establishing a leading position in the world."
However, after careful analysis, the so-called "China's first embedded neural network processor" is likely to be a DSP that can run a neural network, rather than a true neural network dedicated chip .
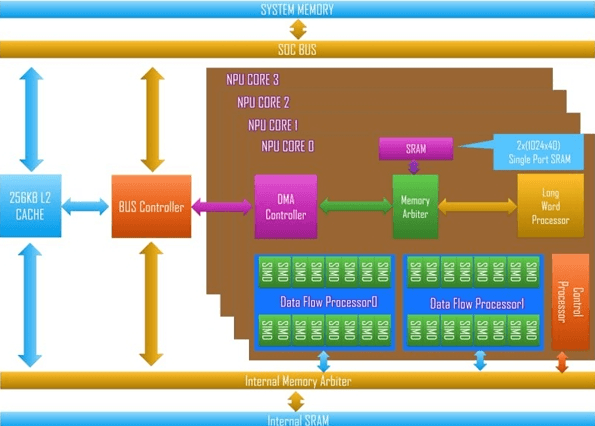
The figure above is the system architecture diagram released by Starlight Smart One.
There are a total of four NPU cores. Each NPU core contains four cores. Each kernel has two stream processors (Dataflow Processors). Each stream processor has eight long or wide 16-bit SIMD units. The peak performance of each NPU core is 38 Gops (16-bit fixed-point) or 76 Gops (8-bit fixed-point). In addition to the multi-core stream processor itself used to complete the convolution operation, Starlight SmartOne integrates a VLIW processor to perform the transcendental functions in the neural network. Another 256KB L2Cache and DMA module are used to move large blocks of data.
From its low-width fixed-point operator, it is inferred that Starlight Intelligence 1 can only support neural network forward operations and cannot support neural network training. From the on-chip storage structure, Starlight Smart One is based on the traditional on-chip cache instead of using scratchpad storage like the most popular neural chip or FPGA solution. Therefore, technically speaking, Starlight Smart One is a typical “new bottled wine†program, which treats traditional DSP processor architectures for digital signal processing to deal with neural networks, and has made corresponding changes in computing devices , such as low levels . Wide and transcendental functions are not "narrow" neural network-specific processors, such as IBM's "True North" chips.
Therefore, Starlight Intelligence One is actually a DSP, not an NPU, which can be applied to a convolutional neural network (CNN) and a network that processes voice and natural language such as a recurrent neural network (RNN) and a long-term short-term memory network (LSTM). It may be powerless.
In other words, Starlight Smart One is only for machine vision tasks for the time being and cannot be used for speech and natural language issues. In fact, this kind of technology idea of ​​adapting neural network using traditional SIMD/DSP architecture has many precedents in the world, even mature products, such as CEVA's XM4 processor, Cadence's Tensilica Vision P5 processor, Synopsys' EV processor and so on.
| NPU: depth learning and health professional chipFrom a technical point of view, deep learning is actually a type of multi-layered large-scale artificial neural network. It is modeled after a biological neural network and is interconnected by several artificial neuron nodes. Neurons connect through the synapses, and synapses record the strength of the links between neurons.
Each neuron can be abstracted as an excitation function whose input is determined by the output of the connected neuron and the synapses connecting the neurons. In order to express specific knowledge, the user usually needs to adjust (by some specific algorithms) the values ​​of synapses in the artificial neural network, the topology of the network, and the like. This process is called "learning." After learning, artificial neural networks can solve specific problems through acquired knowledge.
Since the basic operations of deep learning are the processing of neurons and synapses, the traditional processor instruction set (including x86 and ARM, etc.) was developed for general-purpose calculations. Its basic operations are arithmetic operations (addition, subtraction, multiplication and division) and Logical operations (or with or without) often require hundreds or even thousands of instructions to complete the processing of a neuron, and the processing of deep learning is not efficient. So Google even needs to use tens of thousands of x86 CPU cores for 7 days to train a deep learning neural network that recognizes cat faces. Therefore, traditional processors (including x86 and ARM chips, etc.) are not very efficient for deep learning. At this time, we must find another way to break through the classical von Neumann structure .
Take China's Cambrian as an example, DianNaoYu Directly deals with the processing of large-scale neurons and synapses. One instruction can complete the processing of a group of neurons and provide the transmission of neurons and synapse data on a chip. A series of specialized support.
In addition, the storage and processing in the neural network are integrated and are all reflected by synaptic weights. In the von Neumann architecture, storage and processing are separate, and are implemented by memory and an operator respectively. There is a huge difference between the two. When running neural network applications with existing classical computers based on von Neumann architecture (such as X86 processor and NVIDIA GPU), they are inevitably subject to the separate structure of storage and processing, and thus affect efficiency. This is one of the reasons that specialized chips for artificial intelligence can have certain inherent advantages over traditional chips.
Use numbers to speak, CPU, GPU compared with the NPU, there will be a hundred times more energy than poor performance or distance - to DianNao paper Cambrian team in the past and Inria jointly published as an example - a single-core processor DianNao The main frequency is 0.98GHz, and the peak performance reaches 452 billion neural network operations per second. Under the 65nm process, the power consumption is 0.485W and the area is 3.02 mm 2 mm.
The experimental results on several representative neural networks show that -
DianNao's average performance is more than 100 times that of mainstream CPU cores, but its area and power consumption are only 1/10, and its performance can be improved by up to three orders of magnitude.
DianNao's average performance is comparable to that of mainstream GPGPUs, but its area and power consumption is only one percent of the mainstream GPGPU.

At this stage, traditional chip vendors (such as CPUs, GPUs, and DSPs) attach great importance to the deep learning market. Therefore, they use their huge size and marketing and sales capabilities to promote the use of these traditional chips for deep learning. In essence, it is also fine-tuning the existing technology to adapt the neural network using the traditional SIMD architecture.
However, due to the fact that traditional CPUs, GPUs, and DSPs are not essentially hardware neurons and synapses as the basic processing units, they are inherently inferior to NPUs in deep learning , and in the case of chip integration and manufacturing process levels, Its performance is inevitably inferior to the NPU .
As mentioned above, no matter how good the car is to pull goods, it cannot be compared with real high-powered, high-load trucks.
Lei Feng network (search "Lei Feng network" public concern) Note: This article is an exclusive Lei Feng network article, reproduced, please contact the authorize and retain the source and author, not to delete the content.
Global Lithium-ion Battery Market: Bifurcation
- Based on product, the lithium ion battery market has been categorized into cells/ modules, battery packs, and energy storage systems (ESS).
- On the basis of end-user industry, the global lithium ion battery market is bifurcated into consumer electronics, automotive, and grid energy & industrial.
- In terms of region, the report classifies the market into North America, Europe, Asia Pacific, Middle East & Africa (MEA), and South America. Regions have been analyzed in terms of value and volume shipments in the lithium ion battery market industry. Moreover, region-wise prominent countries covered in the report include the U.S, Canada, Germany, the U.K., France, China, Japan, South Korea, South Africa, GCC, and Brazil.
Global Lithium-ion Battery Market: Rules & Regulations
- As lithium-ion batteries are hazardous material, various regulations regarding the shipment of these batteries have been laid down. The International Air Transport Association (IATA) has set regulations regarding the shipment of lithium-ion batteries in its IATA Dangerous Goods Regulations (DGR).
- Globally, lithium-ion batteries can be shipped as individual cells or group of cells (batteries); batteries/ cell packed with a smartphone or tablet but separated from the electronic equipment and batteries/ cells contained in an equipment.
- Regulations state that, lithium-ion cells and batteries are banned from being transported as cargo or in passenger aircrafts.
- The packaging of lithium-ion batteries must be done in accordance with Packing Instruction (PI) 965. Lithium-ion batteries must be packed in accordance with Section IA or Section IB of PI 965, and must not be packed with the same outer packaging with dangerous goods classified in Class 1 (explosives).
- The packaging of lithium-ion batteries must contain the label [Cargo Aircraft Only," and marked [UN3480." The minimum packaging dimension of packing lithium-ion batteries is 120 mm wide x 110 mm high.
Solar System Batteries,Solar Panel Battery Cost,Enphase Battery Cost,Solar Battery Storage Price
Shenzhen Zhifu New Energy Co., Ltd. , https://www.sunbeambattery.com