
This article was compiled from a blog post published by Adrian Rosebrock on PyImageSearch. The blog post originated from two questions about goal detection that a netizen consulted with the original author:
How to filter or ignore classes that I'm not interested in?
How to add a new class in the target detection model? Is this feasible?
Adrian Rosebrock thinks these two questions are frequently asked by the students who are learning the target test, and he created a unified answer for this article.
Specifically, you will learn about this in this article:
Difference between image classification and target detection;
The composition of the deep learning target detection model, including the difference between the target detection framework and the basic model framework;
How to use a well-trained deep network model for target detection;
How to filter and ignore the categories detected by the deep learning model;
In deep neural networks, there are common pitfalls when adding or removing detection categories.
Want to know more about the deep learning target detection knowledge, or want to solve the doubts related to deep learning target detection, please read on.
▌ Deep Learning Target Detection Guide
Today's blog aims to briefly introduce target detection based on deep learning.
I have tried my best to provide content on the deep learning target detection model, including the OpenCV + Python source code that provides deep learning using a pre-trained target detection model.
Using this guide can help you to get a basic understanding of deep learning goal detection, but at the same time you will also realize that there are many technical details involving target detection that I cannot cover in this blog post.
In other words, we will introduce today's blog content by discussing the essential difference between image classification and target detection, including whether the image classification training model can be used for target detection (and under what circumstances).
Once we understand what the target detection is, we will review the core parts of the deep learning target detection model, including the target detection framework and the basic model. This is the two key parts of the reader who are initially puzzled by the target detection.
Based on this, we will use OpenCV to run a real-time deep learning target detection model.
Without changing the network structure and retraining the model, I will demonstrate how to ignore and filter the target categories that you are not interested in.
Finally, we will discuss how to add or delete categories in deep learning goal detection. We will end this blog today, including the resources I recommend to help you get started.
Let's begin to deepen our understanding of deep learning goals detection!
区别The difference between image classification and target detection

Figure 1: The intuitive difference between classification (left) and target detection (right). For image classification, the entire picture is classified and is a single tag. For the target detection situation, our neural network will locate (potentially multiple) targets in the picture.
When performing standard image classification, specify an input image, and we enter it into our neural network. We will get a class label, or the probability of the corresponding classified label.
This class label is intended to describe the content of the entire image, or at least the most visible content in the image.
For example, as in the input image (left) specified in Figure 1, our convolutional neural network labels the image as "Beagle".
Therefore, we can think of image classification as:
a picture input;
A class label output.
Target detection, whether through deep learning or other computer vision techniques, targets detection based on image classification while trying to pinpoint the position of each target in the image.
When performing target detection, given an input image, we want to be able to obtain:
a list of borders, or the (x, y) coordinates of each target in the image;
Each class corresponds to the class label;
Each frame and class tag has a corresponding probability and confidence score.
Figure 1 (right) gives an example of target detection using deep learning. Note that people and dogs are positioned using bounding boxes and give predictive labels.
Therefore, target detection allows us to:
Enter an image into the network;
Get multiple borders and class labels as output.
Can I use deep learning image classifiers for target detection?

Figure 2: Non-end-to-end deep learning target detection model using the sliding window (left) + combined classification image pyramid (right) method
OK, so at this point you understand the most important differences between image classification and target detection:
When performing image classification, we enter an image into the network and obtain a class label as output;
However, when performing target detection, we enter an image and we will get multiple bounding boxes and class labels.
This question is elicited:
Can we use it for target detection for already trained networks for classification?
The answer is a bit complicated, because it is technically "possible", but the reason is not so simple.
The solution involves:
Using traditional computer vision-based target detection methods (ie, non-deep learning methods), such as sliding windows and image pyramids, such methods are commonly used in target detectors based on HOG features and linear support vector machines;
Get a pre-trained model and use it as the underlying network for the deep learning target detection framework. (eg Faster R-CNN, SSD, YOLO).
Method 1: Traditional Target Detection Methods
The first method is not a pure end-to-end deep learning target detection model.
We use:
A fixed-size sliding window, which slides from left to right and slides from top to bottom to locate targets in different locations;
Image pyramid, used to detect targets at different scales;
Classify by pre-trained convolutional neural networks (classifiers).
In each pause of the sliding window and the image pyramid, we find the region of interest, transmit it to the convolutional neural network, and output the classification of this region.
If the classification probability of the label L is higher than a certain threshold T, we will mark the border of the region of interest as label L. This process is repeated every time the sliding window and image pyramid pauses, and we will obtain the output target detection result. Finally, we use non-maximal suppression on all borders to generate our final output:

Figure 3: Applying non-maximal suppression will suppress overlap and reduce border confidence
This method can be used in some specific use cases, but, in general, this method is slow, tedious, and error-prone.
However, because this method can transform any image classification network into a target detection model, how to use this method is still worthy of study, so as to avoid directly training an end-to-end deep learning target detection model. Depending on your use case, this method can save you a lot of time and effort.
If you are interested in this method of target detection, and would like to learn more about using sliding windows, image pyramids, and image classification methods for target detection content, please see my book, Deep Learning for Computer Vision with Python
Method 2: The basic network of the target detection framework
The second method of deep learning target detection, which treats the pre-trained classification network as the underlying network in the deep learning target detection framework (for example, Faster R-CNN, SSD, or YOLO).
The advantage of doing this is that you can create a complete end-to-end target detection model based on deep learning.
The disadvantage is that this method requires a certain understanding of the working principle of deep learning target detection, which will be discussed in the next section.
ç»„æˆ Elements of deep learning target detection
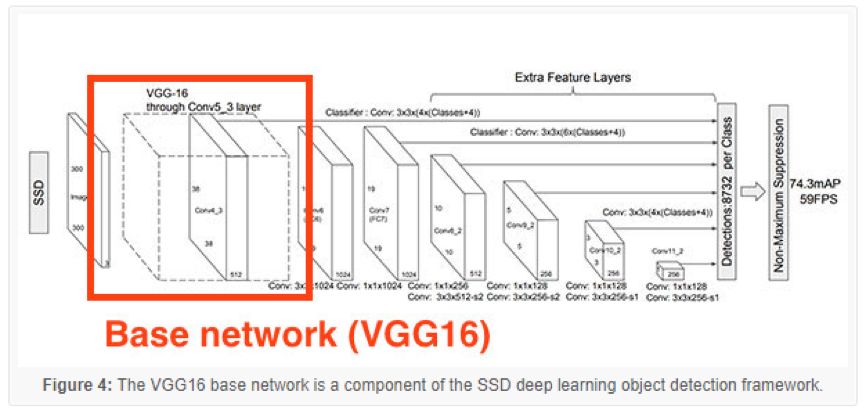
Figure 4: The VGG16 base network is part of the SSD deep learning target detection framework
The deep learning target detection model has many components, sub-components, and secondary sub-components. However, today we focus on two major points. Deep learning objectives detect two points that beginners often confuse:
Target detection framework (eg Faster R-CNN, SSD, YOLO);
The basic network that meets the target detection framework.
You may already know the basic network, which is our common (classifier) ​​convolutional neural network structure, including:
VGGNet
ResNet
MobileNet
DenseNet
In general, in order to learn a rich set of discriminative filters, these networks for image classification have been previously trained in large image data sets (eg, ImageNet).
The target detection framework consists of many components and sub-components.
For example, the framework of Faster R-CNN includes:
Candidate Area Generation Network (RPN);
Candidate window set;
Region of interest ROI pooling layer;
The ultimate region-based convolutional neural network.
When using Single Shot Detectors (SSDs), SSDs include the following components and subcomponents:
MultiBox, borders regression technology;
Priors, a pre-calculated fixed-size border (like the Faster-R-CNN terminology candidate window);
Fixed priors, each feature map unit is associated with a set of default borders of different dimensions and sizes.
Remember, the basic network is just one component that fits the overall deep learning goal detection framework. In Figure 3 at the top of this section, it describes the VGG16 as the underlying network in the SSD framework.
Normally, the basic network is modified. This modification includes:
The basic network is organized into a full convolutional form (that is, an input that can accept any dimension);
Remove the deeper CONV and POOL layers in the underlying network structure and replace them with a series of new layers (SSD), new models (Faster R-CNN), or a combination of both.
The term "network surgery" is a colloquial expression used to indicate that we have eliminated some of the original layers in the underlying network and inserted new layers to replace them.
You may have watched a low-budget horror movie. The murderer in the movie may have carried an ax or a big knife and attacked their victims and attacked them without mercy.
Cyber ​​surgery is more precise and strict than the killer in a typical B-level horror movie.
Network surgery is very strategic. We remove the parts of the network that we don't need and replace it with a new set of components.
Then, when we go to the training framework for target detection, the weights of the following two items have been modified: (1) new layers and modules; (2) basic networks.
Again, a complete review of the workings of various deep learning goal detection frameworks (including the role of the underlying network) is beyond the scope of this blog. If you want to learn more about the deep learning goal detection, including the principles and implementation, please refer to my book, Deep Learning for Computer Vision with Python.
▌ How to evaluate the accuracy of the deep learning target detection model?
When evaluating the performance of the target detection model, the evaluation index we use is the mean accuracy mean (mAP), which is calculated based on the intersection ratio (IoU) of all categories in our dataset.
Convergence ratio (IoU)

Figure 5: In this intuitive example of the crossover ratio IoU, the real value of the border (green) is compared with the predicted border (red). IoU is used together with the average accuracy mAP for accuracy assessment of deep learning target detection. On the right is an equation for calculating IoU
Maybe you will find that IoU and mAP are commonly used to evaluate HOG features + linear SVM detection models, Haar feature cascading classifiers, and performance based on deep learning models; however, keep in mind that the algorithm actually used to generate predictive borders is not important .
Any algorithm used to provide predictive borders (and class labels for reference) as outputs, all of which can be evaluated using IoU. More formally, in order to use IoU to evaluate any target detection model, we need:
1. The border of the real value (that is, the border in the test set, manually labeled by us, where the target object is located);
2. Predicted borders from our model;
3. If you want to calculate the recall rate and precision, you also need the class label of the real value and the class label of the forecast value.
In Figure 4 (left), I give an intuitive example where the border of the real value (green) contrasts with the predicted border (red). IoU is calculated by the equation of Figure 4 (right).
Looking at this equation, you will find that IoU is a simple ratio.
In the numerator part, we calculate the overlap area between the predicted border and the real-value border.
The denominator is the area of ​​the union zone, or more simply, the denominator is the area that is contained by both the predicted border and the actual border.
The intersection area divided by the union area will receive the final score, and the score will be scored.
Mean Average Accuracy (mAP)
In order to evaluate the performance of the target detection model in our data set, we need to calculate the IoU-based mAP:
Based on each class (that is, the average precision of each class);
Based on all categories in the dataset (that is, the average of the average precision values ​​for all categories, the term is the average precision mean)
To calculate the average accuracy of each class, calculate its IoU for all data points in the specified class.
Once we have the IoU calculated with all the data in this category, we can calculate the average accuracy of the class (initial mean).
To calculate the mAP, we calculate the average IoU in all N categories, and then we get the average of N averages (mean of the average precision).
Normally, we use mAP@0.5, mAP@0.5 means that in the test set, in order for the target to be marked as "positive detection sample," the target and the actual value must have an IoU value of at least 0.5 (and are correctly tagged. ). This 0.5 value is adjustable, but 0.5 is the standard value in most target detection data sets and challenges.
深度OpenCV-based deep learning target detection
In previous blogs, we have discussed deep learning goal detection. For the sake of completeness, let us first review the actual source code.
Our example includes the SSD detector and the MobileNet basic network model. GitHub user chuanqi305 trained this model on the COCO dataset.
Let us first review Ezekiel's first question, at the beginning of this article:
How to filter or ignore classes that are not of interest?
This is a very good question. I will use the following sample script to answer.
However, first of all, the following system needs to be prepared:
You need to install OpenCV 3.3 at least in your Python virtual environment (assuming you are using a Python virtual environment). Running the following code requires the DNN module in OpenCV 3.3 or above. Please choose one of the OpenCV installation tutorials on the next page, paying particular attention to the version of OpenCV you have downloaded and installed.
At the same time, you should also install my imutils package. Want to install or update the imutils package in your Python virtual environment, you can simply use
Pip: pip install --upgrade imutils
When you are ready, continue to create a new file named filter_object_detection.py and start:
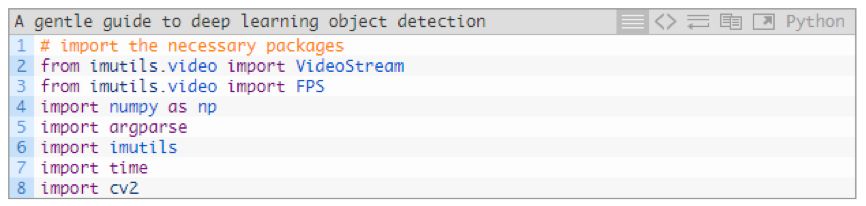
In lines 2~8, we imported necessary add-ons and modules, specifically imutils and OpenCV. I will use the VideoStream class to process the frame image captured from the camera.
We have the necessary tools, and then continue to parse the command line parameters:
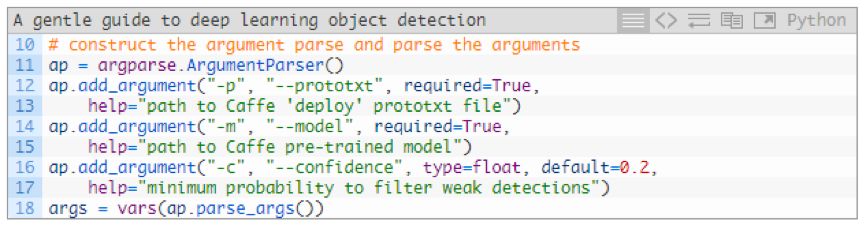
At runtime, our script requires two command line parameters:
--prototxt: Path to the Caffe prototype file. This defines the model definition.
--model: Weighting file path for our CNN model.
.
Alternatively, you can specify --confidence to filter the weak detector threshold.
Our model can predict 21 target categories:

The CLASSES list includes all categories of network training (labels in COCO datasets)
The common confusion about the CLASSES list is:
1. Add new categories to the list;
2. Or, delete the category from the list.
And can automatically let the network "know" what tasks you are trying to accomplish.
But in fact, it's not.
You can't make simple changes to the text labels so that the network can automatically learn to modify, add, and delete untrained data patterns. Neural networks do not work this way.
Here is a quick tip that you can use to filter and ignore prediction tags that you are not interested in.
The solution is:
1. Define the set of IGNORE tags (the list of tags used to train the network, the list you want to filter and ignore);
2. Predict the input image and video frame pictures;
3. Ignore predictions of any class labels contained in the IGNORE collection.
Running in Python, the IGNORE collection is as follows:

Here, we will ignore all prediction targets labeled "people" (the if statement used for filtering will be explained later).
Adding additional elements (class labels in the CLASSES list) is very easy in the collection.
Next, we will generate random labels and border colors, load our model, and start VideoStream:
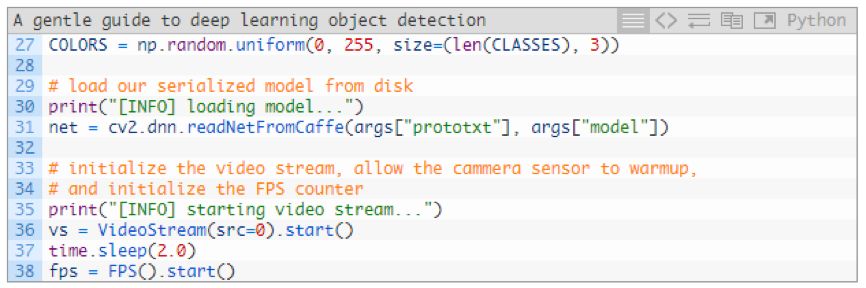
In line 27, a random array of generated COLORS is used to correspond to 21 CLASSES. We will use these colors for subsequent display.
On line 31, we use the cv2.dnn.readNetFromCaffe function and the two command line parameters we need as parameters to pass the loaded Caffe model.
Then we instantiate the VideoStream target as vs and begin our fps count (lines 36-38). 2 seconds of sleep allows our camera to have enough time to prepare.
At this point, we are ready to receive circular input frame images from the camera and input these images into the CNN target detection model:
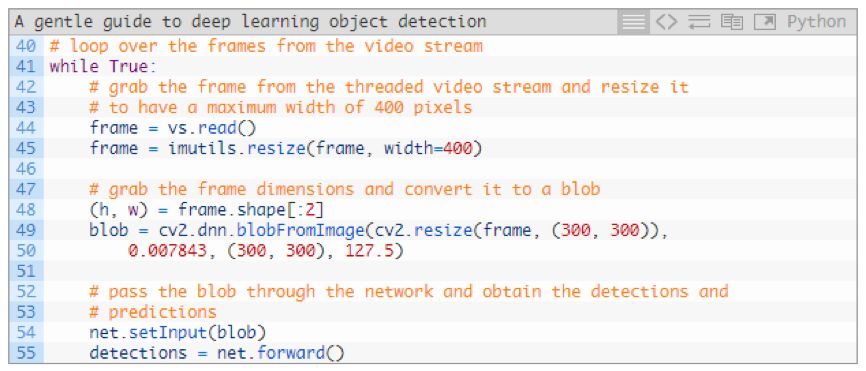
On line 44, we read the image and resize the image while preserving the aspect ratio of the display (line 45).
Here, we extracted the height and width values ​​due to later needs.
Lines 48 and 49 generate a blob from the frame image.
Next, we enter the blob into the neural net for target detection. (lines 54 and 55)
Let's loop through the detection model:
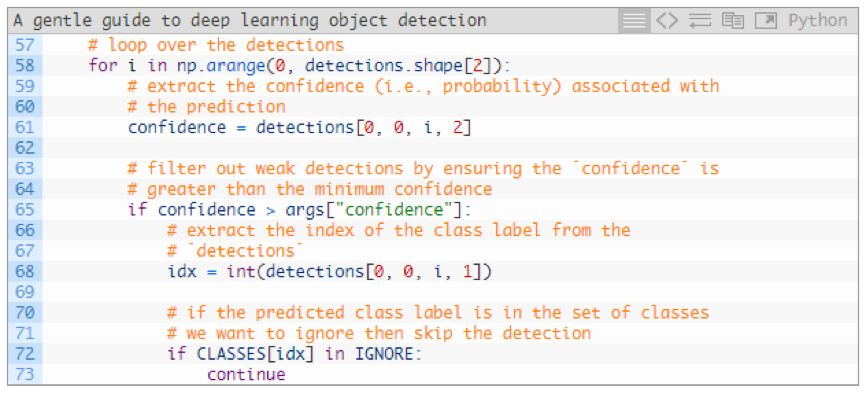
On line 58, we will start the loop of the detector.
In each test, we extracted confidence (line 61) and compared it to our confidence threshold (line 65).
If our confidence is greater than the minimum value (the default value is 0.2, which can be modified via command line parameters) this test result will be treated as a positive test result, effectively detecting and continuing further processing.
First, we extract the index of the class label extracted from the inspection model (line 68).
Then, reviewing Ezekiel's first question, we can ignore the list in the IGNORE collection, on lines 72 and 73. If this is a category that is ignored, we will simply continue back to the initial cycle of the detection model (we do not show the label or border of this category). This achieved a "quick crack" solution.
Otherwise, when we detect the target in the white list, we need to display the target's class labels and rectangles in the frame picture:
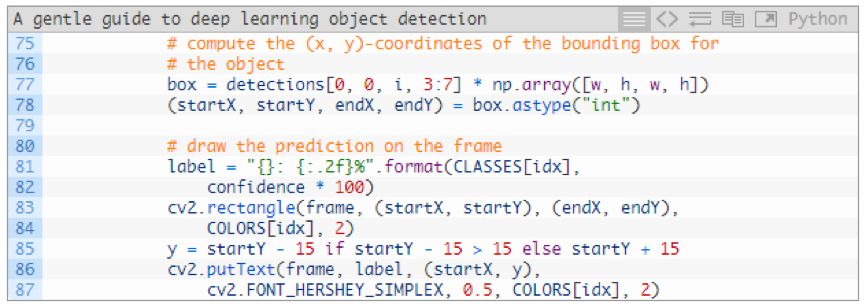
In this code module, we extract the border coordinates (lines 77 and 78), and then draw the class labels and rectangles on the frame image (lines 81-87).
The colors of the labels in the same class are the same as the rectangles. The targets in the same category will use the same color (that is, the "boats" in the video will use the same color labels and borders).
Finally, while still in the while loop, we will present the results of our hard work on the screen:
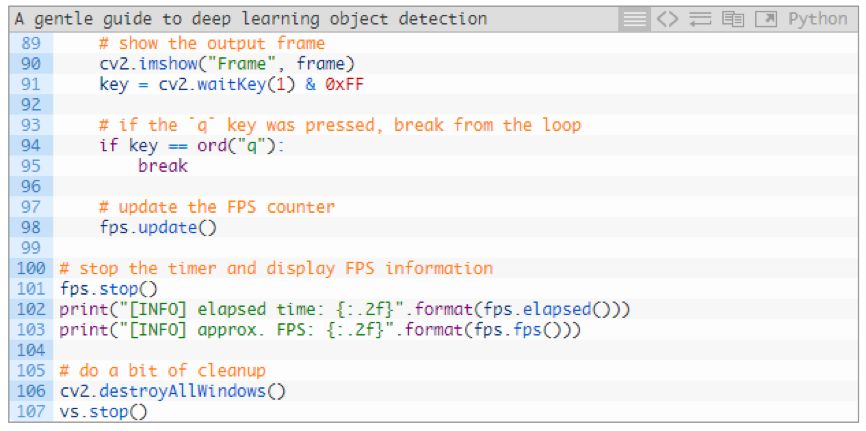
In lines 90 and 91, we show the frame picture and capture the key input.
If you press the "q" key, we stop and roll out the loop (lines 94 and 95)
Otherwise, we continue to update the fps counter (line 98) and continue to extract and process frame pictures.
In the rest of the code line, when the loop stops, we will display the time and degree of frames per second and clear it.
Run your deep learning target detection model
Run the script, open the terminal and go to the code and model directory, from where it runs the next command:


Figure 6: Real-time deep learning target detection demo using the same model. In the right video, I programmed to ignore specific target categories.
In the above GIF, you can see from the left that the "person" category is detected because my IGNORE collection is empty. On the right side, you will find that I have not been detected because of adding the "person" class to the IGNORE collection.
Although our deep learning target detectors technically still detect the "person" category, our post-processing code can filter out this category.
Have you encountered an error while running the deep learning target detection model?
The first step in troubleshooting is to check if you have connected a camera. If this is not the problem, you may see the following error message in the terminal:

If you see this message, then you did not pass "command line arguments" to the program. If PyImageSearch readers are unfamiliar with Python, argparse, and command-line arguments, this will be a common problem for them.
▌ How can I add and remove classes in the deep learning target detection model?

Figure 7: Fine-tuning and migration learning of deep learning target detection models
As I mentioned in this guide, you cannot simply modify the CLASSES list to add and remove class labels. The underlying network itself has not changed.
What you do, at best, is just modifying a class label text file.
Conversely, if you want to add or remove classes from a neural network, you need to:
1. Retraining;
2. Make fine adjustments.
Retraining is often a time-consuming and costly operation. Therefore, we try to avoid retraining as much as possible, but in some cases, starting from the beginning can not be avoided.
Another way is to fine-tune the network.
Fine-tuning is a form of migration learning. Fine-tuning can be accomplished through the following process:
1. Remove the full connection layer for classification and marking;
2. Replace it with a completely new, randomly initialized fully connected layer.
We can also modify other layers in the network (including freezing the weights of certain layers and thaw them during training).
Specifically how to train your custom deep learning target detection model (including fine-tuning and retraining), this article does not cover such advanced topics, but you can refer to the following sections to help you get started.
Summary
In today's blog, I have outlined the complex issues involved in the detection of deep learning goals. We first review the essential differences between image classification and target detection, including how we use network for image classification training for target detection.
Then, we reviewed the core part of deep learning target detection:
frame
Basic model
The basic model is usually a pre-trained network (classifier), usually trained in large image data sets, such as ImageNet, in order to allow the network to learn a robust set of decision filters.
We can also retrain the basic network, but this usually requires a long training time, and the target detection model can achieve reasonable accuracy.
In most cases, you should start with a pre-trained basic model instead of retraining.
Once we have a deep understanding of the deep learning target detection model, we can run the real-time target detection model in OpenCV.
I also showed you what to do to filter or ignore class tags that you are not interested in.
Finally, we learned that adding or deleting a class from a deep learning target detection model is not as easy as adding or subtracting a class tag from a hard-coded class tag list.
The neural network itself does not care whether you have modified the list of class labels. Instead, you will need to:
Modify the network structure itself, remove the fully connected class prediction layer, and fine-tune it;
Or retrain the target detection framework.
For most of the deep learning target detection items, you will start with a deep learning target detection model that has been previously trained in the target detection task (such as COCO), and then obtain your own detection model by fine-tuning the model.
The USB 3.2 specification absorbed all prior 3.x specifications. USB 3.2 identifies three transfer rates – 20Gbps, 10Gbps, and 5Gbps.
Key characteristics of the USB 3.2 specification include:
Defines multi-lane operation for new USB 3.2 hosts and devices, allowing for up to two lanes of 10Gbps operation to realize a 20Gbps data transfer rate, without sacrificing cable length
Delivers compelling performance boosts to meet requirements for demanding USB storage, display, and docking applications
Continued use of existing USB physical layer data rates and encoding techniques
Minor update to hub specification to address increased performance and assure seamless transitions between single and two-lane operation
Improved data encoding for more efficient data transfer leading to higher through-put and improved I/O power efficiency
Backwards compatible with all existing USB products; will operate at lowest common speed capability
Usb 3.2 Cable,Usb Type-C Cable,5Gbps Usb Type-C Cable,10Gbps Usb Type-C Cable
UCOAX , https://www.ucoax.com