In the past few decades, in-depth learning, as the number one seed in the field of artificial intelligence, has become an exciting technological innovation. In areas where traditional software models are difficult to solve, such as speech recognition, cancer detection, etc., deep learning has begun to take shape.
The principle of deep learning is often used to compare with the process of human learning. Experts believe that the deep learning process will be faster and more deeply extended to more fields. In some cases, people may worry that deep learning will threaten humanity’s critical status in social and economic life and cause consequences such as unemployment and even human beings enslaved by machines.
There is no doubt that machine learning and deep learning are very effective for certain tasks. However, it is not a master key that can solve all problems and override all technologies. In fact, there are still many constraints and challenges compared to the concept of over-hype exaggeration, which makes the technology in some aspects still not enough to meet humanity, and even unable to reach the capabilities of human children.
Let us recall the childhood experience of childhood: The first time we contacted Super Marie, it took only a few hours to initially form a shallow concept of a platform game. The next time you play a similar game (such as prince of persia, sonic hedgehog, crash bandicoot, or donkye kong country), you will be able to apply the practical experience you previously had in Super Mario games. If they later upgrade to a 3d version (as it appeared in the mid-1990s), they can also get started without much effort. At the same time, it is also easy to apply real-life experiences to the game. When I encounter a deep pit, I immediately know that I must operate Mario to skip it. When I meet a barbed plant, I immediately know that I must avoid it.
We are not a good game player, but for deep learning algorithms, completing the above process is full of challenges. Even the smartest game algorithms must learn from scratch.
Human beings can draw on and learn from different concepts through abstraction, analogy, and deduction, and achieve the same effect. Deep learning algorithms do not do this. It requires a lot of precise training to achieve.
In a recent article entitled “Objective Evaluation of Deep Learningâ€, former Uber AI leader, New York University professor Gray Marcus, described limitations and challenges in deep learning, and he elaborated on the principles and foundations of deep learning. The limitations of deep learning, but also expressed eager expectations for the future challenges.
The principle of deep learning
Through the abstract summary and simulation of the method used to process information in the human brain, the concept of neural network is proposed. Unprocessed data (images, sound information, or textual information) is input to the "input unit" of the output layer; the input information is output to the "output node" of the output layer after a certain mapping. The mapping method is based on the user's definition. For example, the input picture has a cat and the input sound segment has "hello". Deep learning is an algorithm architecture that extracts and expresses information through multi-layer neural networks and implements complex tasks such as classification and detection. As a core component of deep learning algorithm, deep neural network contains multiple layers of hidden layers between the input and output layers, so that the algorithm can complete complex classification relationships.
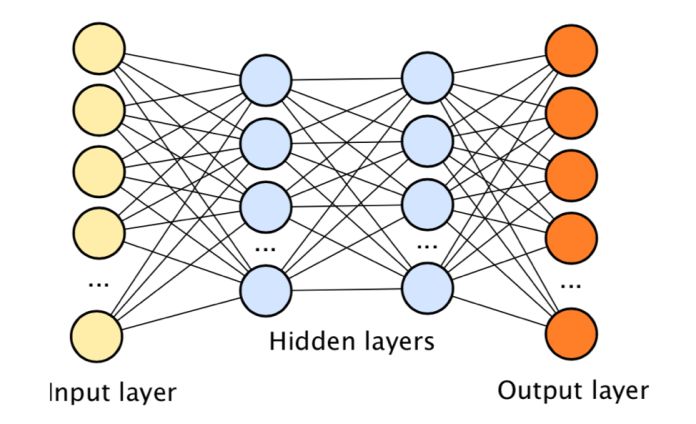
Figure: Schematic diagram of deep neural network structure
Deep learning algorithms require a lot of data to train. For example, if you want to accurately identify from the image whether it contains “cats,†you need to train it with thousands of pictures in advance. The greater the amount of training data, the higher the accuracy of the model. Big companies are scrambling for data at all costs and are even willing to provide services for free in exchange for data. The more data you have, the higher the accuracy of the algorithm and the more effective the service, and will attract more users, thus creating a virtuous circle in the competition.
Deep learning requires a lot of data fuel
If in a world with unlimited data and computing resources, there is no need for the existence of technologies other than machine learning. But it is clear that the real world is not the case. Machine learning algorithms can never be comprehensive, and they must be given interpolation or deduction to give possible answers to sounds they have never heard or seen.

For deep learning algorithms, there is a lack of "defined" processes, both from special to general refining processes, and good results must be based on thousands or even more training samples.
So what happens if you can't do a lot of effective training? The answer is: staggering mistakes! The wrong algorithm may not be able to distinguish between robbers and helicopters, gorillas and humans.

Deep learning error recognition example
Excessive reliance on data also raises security issues. Marcus said: "Deep learning is very good at judging the vast majority of phenomena in a particular field. On the other hand, it can also be fooled." This involves attacking samples against deep learning algorithms. By making minor changes to the traffic signs, the deep learning algorithm will misjudge traffic signs for stopping and speeding, and may not be able to differentiate between sand piles and flesh-colored knitwear.
Deep learning is not profound
Deep learning is good at establishing the mapping relationship between input and output, but it is not good at summarizing and discovering the internal physical connection. In fact, the concept of "depth" is only for the architecture of a multi-layer hidden layer, and it does not mean how deep the algorithm understands the object itself. Marcus believes that "systems constructed through such algorithms cannot summarize and abstractly understand concepts such as justice, democracy, and intervention."
Returning to the game case mentioned in the introductory article, through extensive training, the deep learning algorithm can defeat the best human Super Mario player. However, this does not mean that the artificial intelligence has the same ability to comprehend the game as a human. When a baseball When stumbling to Mario, gamers all know that by jumping up and avoiding, artificial intelligence only knows how to stupidly run forward until it is hit by baseball. Through repeated trial and error experiments, it can guarantee the final winning rate, but slightly upgrade the following games or change versions, artificial intelligence must learn from scratch.
Marcus's article mentions the application case in Google Deep Learning: In the mastering of atari game breakout, 240 minutes after the game is played, the best way to win the game is to tunnel on the wall. However, it does not understand the wall, or what the tunnel is. It is only through repeated trial and error experiments until it can get the highest score in the shortest time.

Deep learning is the algorithm black box
The results given by the program written according to the rules can be traced to the last if else. Machine learning and deep learning algorithms do not. This opaque nature is defined as a "black box" problem. The deep learning algorithm establishes a mapping between thousands of nodes and gives the relationship between input and output. Even the natural engineer who developed this algorithm often confused the results. When deep learning is applied to systems with higher fault tolerance, this shortcoming does not seem to matter. But imagine that if it is applied to the fate of the court to determine the suspect's fate, or in the field of medical treatment that determines the treatment of the patient, any minor mistake can lead to irreversible and fatal results.
Marcus said: "The transparency problem in deep learning algorithms has not been solved so far, and it has seriously hampered its development in fields such as financial transactions and medical diagnosis.
Based on the results of the training of large amounts of data, the methods of deep learning often show certain prejudices. For example, men earn more than women, and white people have more appearance advantages than black people. This kind of error is hard to find in the debugging stage of the program, but it often causes widespread public concern and discussion due to the results it gives.
Deep learning is doomed to fail?
of course not! But it needs real test.
Marcus thinks: "Deep learning can be used as a perfect way to simplify complex problems, based on a large amount of data, and establish a mapping between input and output." With proper choice of training methods and sufficient training samples, deep learning can be used as an efficient means of classifying data. However, it does not possess magical power. It is necessary to understand its application limitations and effectiveness. Marcus also believes that deep learning needs to be combined with other technologies, such as regular rule-based programming or other artificial intelligence technologies such as reinforcement learning. Starmind's Pascal Kaufmann believes that by using neuroscience, artificial intelligence can be learned like humans, and it may be an effective method.
In the end, I will use Marcus's words to conclude the full text and elicit a reflection on where to go for deep learning: “Deep learning will not and shouldn’t disappear, but testing the ability and inability of deep learning in a five-year period, and let the community fully accept and understand Its capabilities and limitations have important implications for both the technology itself and the development of society!"
Static Frequency Connerter With Threephase Output
Variable Frequency Inverter,Variable Frequency Converter,3 Phase Frequency Converter,Frequency Converter 60Hz To 50Hz 3 Phase
Jinan Xinyuhua Energy Technology Co.,Ltd , https://www.xyhenergy.com